
Keras系列(一)
开始使用Keras
关于Keras API
Keras 是一个用于构建和训练深度学习模型的高阶 API。它可用于快速设计原型、高级研究和生产,具有以下三个主要优势:
-
方便用户使用: Keras 具有针对常见用例做出优化的简单而一致的界面。它可针对用户错误提供切实可行的清晰反馈。
-
模块化和可组合: 将可配置的构造块连接在一起就可以构建 Keras 模型,并且几乎不受限制。
-
易于扩展:可以编写自定义构造块以表达新的研究创意,并且可以创建新层、损失函数并开发先进的模型。
这里还要提一下的是Estimators API,是在版本1.1中添加到Tensorflow中的,它提供了对较低级别Tensorflow核心操作的高级抽象。 它与Estimator实例一起使用,该实例是TensorFlow对完整模型的高级表示。 Keras与Estimators API相似之处在于,它抽象化了深度学习模型组件,如层 layers, 激活函数activation functions 和优化器optimizers,使开发人员更容易使用。 它是一个模型级别的库,不处理低级操作,低级操作是张量操作库或后端的工作。 Keras支持三个后端–Tensorflow,Theano和CNTK。 Keras在版本1.4.0(2017年11月2日)之前不属于Tensorflow的一部分,直到版本1.4.0,Keras才是Tensorflow的一部分。现在,当您使用tf.Keras(或者谈论’Tensorflow Keras’)时,您只需使用Keras接口和Tensorflow后端来构建和训练您的模型。
因此,Estimator API和Keras API都在低级核心Tensorflow API之上提供了更高级的API,您可以使用其中任何一个来训练您的模型。
目前(2021-01-04)根据一些学习练习情况,查的一些资料也建议是 如果是tf1.0, 建议使用estimator,tf2.0以上建议使用keras API。
这里提供了Keras的R接口的文档。参见Keras的主要网站 https://keras.io 查询有关该项目的更多信息。
安装Keras
下面的方法可以为您提供基于默认cpu的Keras和TensorFlow安装。如果你想要一个更自定义的安装,例如,如果你想利用NVIDIA gpu,请参阅install_keras()和安装部分的文档
install.packages("keras")
# 或者
# devtools::install_github("rstudio/keras")
library("keras")
install_keras()
MNIST数据练习
我们可以通过一个简单的例子来学习Keras的基础知识:从MNIST数据集识别手写数字。MNIST由28 x 28灰度图像的手写数字像这样:

据集还包括每个图像的标签,告诉我们它是哪个数字。例如,上面图像的标签是5、0、4和1。
准备数据
Keras包含了MNIST数据集,可以使用dataset_mist()函数访问它。这里我们加载数据集,然后为我们的测试和训练数据创建变量:
library(keras)
mnist <- dataset_mnist()
x_train <- mnist$train$x
y_train <- mnist$train$y
x_test <- mnist$test$x
y_test <- mnist$test$y
x数据是灰度值的三维阵列(图像、宽度、高度)。为了准备用于训练的数据,我们将3-d阵列转换为矩阵,方法是将宽度和高度重塑为单个维度(28x28张图像被平展为长度784个向量)。然后,我们将0到255之间的灰度值转换为0到1之间的浮点值:
# reshape
x_train <- array_reshape(x_train, c(nrow(x_train), 784))
x_test <- array_reshape(x_test, c(nrow(x_test), 784))
# rescale
x_train <- x_train / 255
x_test <- x_test / 255
注意,我们使用array_reshape()函数而不是dim<-()函数来重塑数组。这样就可以使用行主语义(c-style),而不是R的默认列主语义(fortan-style),重新解释数据,这与Keras调用的数字库解释数组维度的方式兼容。
y数据为整数向量,取值范围为0 ~ 9。为了准备这些数据用于训练,我们使用Keras的to_categorical()函数一次性将这些向量编码成二进制类矩阵:
y_train <- to_categorical(y_train, 10)
y_test <- to_categorical(y_test, 10)
定义模型
Keras的核心数据结构是一个模型,一种组织层的方法。最简单的模型类型是顺序模型(Sequential model),一种由层组成的线性堆栈。Kersa还有另一种叫做Model模型,用来建立更复杂的模型。
我们首先创建一个顺序模型,然后使用管道操作符(%>%)添加层:
model<-keras_model_sequential()
model %>%
layer_dense(units =256,activation='relu',input_shape=c(784)) %>%
layer_dropout(rate=0.4) %>%
layer_dense(units=128,activation='relu') %>%
layer_dropout(rate=0.3) %>%
layer_dense(units=10, activation='softmax')
第一和第三层都是密度连接层(layer_dense),采用的激活函数是relu,但是设置的神经元数目参数不一致,并且第一层还起到输入层的作用,input_shape参数指定输入数据的形状(表示灰度图像的长度为784的数字向量)。
第二和第四层是两个丢包层(dropout),训练过程中随机“Dropout”(即设置为零)该层的一些输出特征组成,通常用来避免过拟合而加快收敛速度。
最后一层使用softmax激活函数输出长度为10的数字向量(每个数字的概率)。
接下来,使用适当的损失函数(Losses)、优化器 (Optimizers)和指标 (Metrics)编译模型。这里设置的损失函数(loss)是categorical_crossentropy,它适用于目标是分类格式的数据(例如,如果你有10个类,每个样本的目标应该是一个10维向量,除了在对应于样本的类的索引处有一个1之外都是零);设置的优化器(loss)是RMSProp,通过引入一个衰减系数,使每一回合都衰减一定比例,使用它的默认参数;设置的指标(metrics)是精确度accuracy。
model %>% compile(
loss = 'categorical_crossentropy',
optimizer = optimizer_rmsprop(),
metrics = c('accuracy')
)
训练和评估模型
使用fit()函数对模型进行30个epoch的训练,使用每批量包含128张图像。
history <- model %>% fit(
x_train, y_train,
epochs = 30, batch_size = 128,
validation_split = 0.2
)
注意的是,通常不会在每个epoch之后重新对验证集(validation set)进行取样。如果你这样做,你的模型会在你数据集中的每个样本上训练,因此这会导致过拟合。所以,希望在训练过程之前分割你的数据,然后算法应该只使用训练数据的子集进行训练,validation_split用来设定作为验证数据的训练数据的分比例。设计的函数确保数据以这样一种方式分离,即它总是针对每个epoch训练数据的相同部分。如果该选项被选择,那么所有的洗牌都是在两个epochs之间的训练样本内完成的。
fit()返回的历史对象包括损失和精度指标,我们可以绘制。
plot(history)
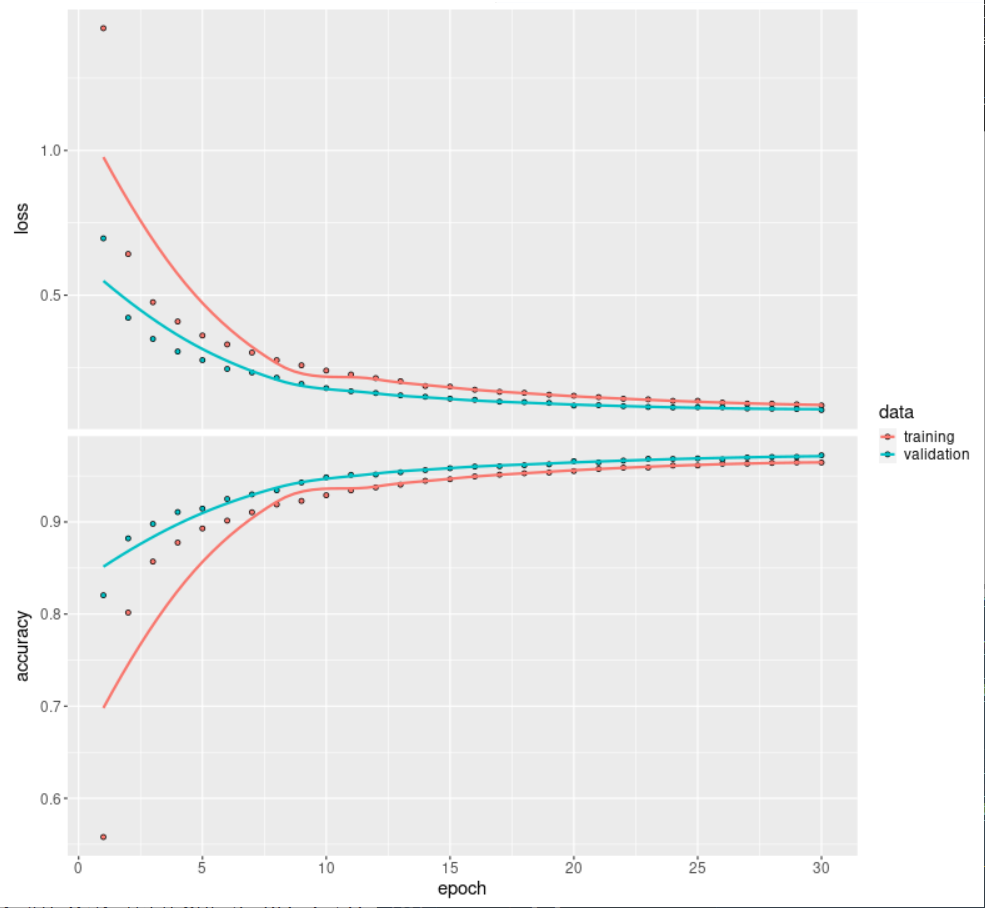
对测试数据进行模型性能评估:
model %>% evaluate(x_test, y_test)
# loss accuracy
# 0.1030627 0.9714000
对新数据产生预测:
model %>% predict_classes(x_test)
MNIST 的卷积神经网络
尝试学习用TensorFlow 搭建一个卷积神经格络(CNN)模型,并用它来训练MNIST 数据集。
待完成~~~~~~~~~~~~~~~~